MicroService Architecture
web APIs
communication using
language-agnostic apis
independently deployable to
Amazon, Azure, ...
practice decentralized data
management
continuous integration (not
weekly, monthly schedule releases)
native to agile processes
evoluable and scalable
architectures
organized around business
capabilities
microservices is NOT FE, MT
and BE
microservices is split into
business capabilities
microservices is optimized
for replaceability
microservices technology
heterogeneous, partitioned scalability, independent deployment
CON for microservices:
additional servers
container (zero overhead)
over VM
micro-s needs no shared data
(limited sharing)
solution: bounded context
a domain consists of multiple
bounded contexts.
book: domain-driven design
No shared state = no
distribute transactions
http://vasters.com/clemensv/2012/09/01/Sagas.aspx
good old redundancy; isolate
the failure
multiple connection pools
isolation (limit
inter-service dependencies)
circuit breakers (time out,
use cache, block the incoming traffic)
security - containers and api gateway
As microservices replace monolithic applications, they're
proving to be more flexible, but also more complex to secure and protect
http://katrinatester.blogspot.com/2015/09/api-web-services-microservices-testing.html
TUESDAY,
8 SEPTEMBER 2015
API, Web Services & Microservices
Testing Pathway
This pathway is a tool to help
guide your self development in API, web services and microservices
testing. It includes a variety of steps that you may approach linearly or
by hopping about to those that interest you most.
Each step includes:
▪
links to a few resources as a
starting point, but you are likely to need to do your own additional research
as you explore each topic.
▪
a suggested exercise or two, which
focus on reflection, practical application and discussion, as a tool to connect
the resources with your reality.
Take your time. Dig deep into areas
that interest you. Apply what you learn as you go.
▪
STEP - Distinguishing APIs and web
services
An API (Application Programming
Interface) is the means by which third parties can write code that interfaces
with other code. A Web Service is a type of API that:
o
is used to exchange data between
applications,
o
uses a standard defined by
W3C,
o
has an interface that is depicted
in a machine-processable format usually specified as a WSDL (Web Service
Description Language), and
o
almost always operates over HTTP.
Example web service protocols
include SOAP, REST, and XML-RPC. An example of an API that is not a web service
is the Linux Kernel API, which is written in C for use on a local machine.
References: API vs Web Service, Difference between web
API and web service, Difference between API
and web service
o
2013 - What APIs Are And Why They're Important - Brian Proffitt
o
2006 - What are web services (section) - Nicholas Chase
o
2005 - Introduction to Web
Services (PDF) - Ioannis G. Baltopoulos
EXERCISE
[1 hour] Once you feel that you understand the difference between APIs and
web services, talk to a developer. Ask what APIs and web services exist within
the application that you're working on. Work with your developer to draw a
simple architecture diagram that shows whereabouts in your application these
interfaces are located. Be sure you can distinguish which are APIs and which
are web services, and that you know which protocols each interface uses.
STEP - Understanding SOAP and REST
Learn more about two common
implementations of web services and the differences between them:
•
2006 - Understanding SOAP (section) - Nicholas Chase
•
What is REST? (video) - Todd Fredrich
•
2013 - Understanding SOAP and
REST Basics And Differences - John Mueller
•
2008 - How to GET a cup of
coffee - Jim Webber, Savas Parastatidis & Ian Robinson
EXERCISE
[1 hour] Find out whether you have any services with both a SOAP and a
REST implementation. This means that the same business operation can be served
in two different formats through two different APIs. Talk to a developer or
technical lead and ask them to demonstrate a request in each implementation.
Discuss the differences between these two interfaces and some of the reasons
that both exist.
STEP - API and web service testing
Discover the tools available and
some common mnemonics to approach web service testing:
•
2014 - API Testing: Why it matters and how to do it - Michael Churchman
•
2013 - Johnny mnemonic -
ICEOVERMAD - Ash Winter
•
The API Testing Dojo - Smart Bear
•
2015 - API Testing: UI Tools - Avinash Shetty
•
2015 - API Testing: Developer Tools - Avinash Shetty
•
2015 - WTEU-53 - An introduction to API Testing - Amy Phillips
•
2015 - Some API Testing Basic
Introductory Notes and Tools - Alan
Richardson
EXERCISES
[3 hours] Repeat the 53rd Weekend Testing Europe session by running some
comparative tests on the SongKick API and associated website. SongKick is a
service that matches users to live music events taking place near them. Use
your web browser to make API requests as you would a website URL. Alongside the
links from Amy Phillips and Alan Richardson above, you can refer to the SongKick API and the full
transcript of the weekend testing Europe session for guidance.
Experiment with locating different test data and using different API requests
until you understand how the API functions. Please abide by all terms of use
and do not experiment with load or security testing on this API.
[3 hours] Install Postman and use it to test the TradeMe
Sandbox API. TradeMe is the leading online marketplace and classified advertising
platform in New Zealand. Public, unregistered, access to their developer API is
restricted to catalogue
methods. Experiment with retrieving information and compare your results against
the TradeMe
Sandbox site. Please abide by all terms of use and do not experiment with load or
security testing on this API.
[3 hours] Explore the Predic8 online REST web services
demo using the advanced
REST client Chrome extension or PAW - the ultimate REST client for Mac. You will need to
install your chosen software and read the supporting documentation for the
demonstration REST service. Explore the different functions provided. In
addition to retrieving information you should be able to modify data using
POST, PUT and DELETE requests. Please abide by all terms of use and do not
experiment with load or security testing on this API.
[3 hours] Select an API or web service within your application. Seek out
the reference material to discover what requests are allowed. Apply what you've
learned through testing the third party APIs to compare the behaviour of your
internal interfaces and application. Use the tools you've tried before, or
select a different tool to explore. Afterwards, discuss your testing with a
developer or another tester within your team, share what you found and ask how
this interface is tested now.
STEP - Technical implementation of
REST API
Get a deeper understanding of REST
APIs by understanding how they are designed and implemented:
•
2014 - How to design a REST API - Antoine Chantalou, Jérémy Buisson, Mohamed Kissa, Florent
Jaby, Nicolas Laurent, Augustin Grimprel, Benoit Lafontaine
•
2014 - The commoditization of
the user interface - Todd Friedrich
•
2014 - REST API application
layers - Todd Friedrich
•
2014 - REST API design:
Resource modeling - Prakash Subramaniam
•
2010 - Richardson maturity
model - Martin Fowler
EXERCISE
[3 hours] Create a set of requests using a REST API within your
organisation. Investigate how resources are modeled, e.g. resource URL, HTTP
verbs (GET PUT DELETE POST). Talk to a developer or technical lead to check
your understanding and ask questions about your REST implementation.
STEP - Security testing APIs
Explore the basics of security
testing APIs:
•
2015 - How to Hack an API and
Get Away with It (Part 1 of 3) - Ole Lensmar
•
2015 - How to Hack an API and
Get Away with It (Part 2 of 3) - Ole Lensmar
•
2015 - How to Hack an API and
Get Away with It (Part 3 of 3) - Ole Lensmar
•
2015 - WTEU-56 – Security testing for APIs - Dan Billing
EXERCISE
[8 hours] Repeat the 56th Weekend
Testing Europe session by investigating the deliberately insecure API for the Supercar
Showdown website, which forms the basis of Troy
Hunt’s Pluralsight Course Hack Your API First. Alongside the write-up from Dan
Billing above, you can refer to the Hack Your API First
course materials and the full transcript of the
Weekend Testing Europe session for guidance.
Alongside the course materials, conduct your own experiments with the different
facets of API security.
[3 hours] Apply what you've learned to assess the security of one of your
APIs in a development or test environment, not production. Document any
vulnerabilities that you discover to discuss with your development team. Talk
to an architect about additional protection that is in place in your production
environments to prevent attacks.
STEP - Service virtualization
Discover service virtualization and
how it can be used in testing:
•
What is service
virtualization - John Mueller
•
2014 - Hardening Your
Application Against API Failures with API Virtualization - Lorinda Brandon
•
2015 - 4 Ways to Boost Your
Test Process with Service Virtualization - Bas
Dijkstra
EXERCISE
[2 hours] Determine whether any of your test suites use service
virtualization. Draw a detailed architecture diagram that reflects your
understanding of where services are virtualized and how this has been
implemented. Check your understanding with a developer or another tester and
make sure you understand the reasons that the tests use service virtualization.
STEP - Introduction to
microservices
These articles give an introduction
to microservices and share practical experiences from organisations who use
them:
•
2014 - Microservices - Martin Fowler
•
2015 - Introduction to
microservices - Chris Richardson
•
2015 - Delving into the
Microservices Architecture - John Mueller
•
2014 - How we build
microservices at Karma - Stefan Borsje
•
2015 - Why 2015 will be the
year of microservices - Eric Knorr
EXERCISE
[1 hour] Talk to a developer or
technical lead to check your understanding of microservices, then discuss the
benefits and drawbacks of switching to a microservices architecture.
STEP - Microservices testing
Discover how to test in a
microservices world:
•
Testing Strategies in a
Microservice Architecture - Toby Clemson et al.
•
2015 - Performance Issue
Considerations for Microservices APIs - John Mueller
•
2014 - 8 Questions You Need to
Ask About Microservices, Containers & Docker in 2015 - Andrew Phillips
•
2009 - Integration tests are a
scam - JB Rainsberger
•
2014 - Throw away your
integration tests (slides) - Beth Skurrie
EXERCISE
[1 hour] Demonstrate your understanding of microservices testing by
describing to another tester or test lead, in your own words, the types of
testing that are possible in a microservices architecture.
STEP - A broader look at APIs
A brief introduction to API management
and APIs within IoT, hypermedia, machine learning, etc.
•
2012 - What is API management
- A Brief Primer - Navdeep Sidhu
•
2013 - API management platform capabilities - Jeevak Kasarkod
•
2015 - The API is the
Invisible Hand Behind the Internet of Things -
Jennifer Riggins
•
2014 - Working with Hypermedia
APIs - John Mueller
•
2015 - Testing Challenges
Associated with Machine Learning APIs - John Mueller
EXERCISE
[1 hour] Talk to a developer or technical lead about the future direction
for our API implementation. Discuss how your organisation might be impacted by
these ideas, or other innovations.
http://martinfowler.com/articles/microservices.html
Contents
Characteristics of a Microservice
Architecture
▪
Componentization via Services
▪
Organized around Business
Capabilities
▪
Products not Projects
▪
Smart endpoints and dumb pipes
▪
Decentralized Governance
▪
Decentralized Data Management
▪
Infrastructure Automation
▪
Design for failure
▪
Evolutionary Design
▪ Are
Microservices the Future?
Sidebars
▪ How big is a microservice?
▪ Microservices and SOA
▪ Many languages, many options
▪ Battle-tested standards and enforced standards
▪ Make it easy to do the right thing
▪ The circuit breaker and production ready code
Synchronous calls considered
harmful
Jennifer Riggins
Jennifer, as a marketer and writer, helps individuals and
small businesses develop their vision and brand, turning it into an actionable,
profitable future. She especially loves working with start-ups, SaaS and
Spain-based innovators.
While microservices is still more of
a concept than a predefined architecture with specific requirements, Lewis and
Fowler say there are certain attributes that typically come with microservices, including:
▪
Componentization as a Service: bringing certain components together to make a customized
service.
▪
Organized Around Business
Capabilities: segregating capabilities for specific business areas
like user interface and external integrations.
▪
Development Process is Based on
Products Not Projects: following Amazon’s “eat your own
dog food,” developers stay with the software for the product’s lifetime.
▪
Smart Endpoints and Dumb Pipes: each microservice is as decoupled as possible with its own
domain logic.
▪
Decentralized Governance: enabling developer choice to build on preferred languages for
each component.
▪
Decentralized Data Management: having each microservice label and handle data differently.
▪
Infrastructure Automation: including automated deployment up the pipeline.
▪
Design for Failure: meaning that more ongoing testing of “what if” has to occur to
prepare for failure.
Where Do Microservices Win?
As we move into a more specialized
world and user experience, microservices, in some ways, make for a better developer experience too, which
allows you to grow your business more rapidly.
More and more people
are flocking to try the microservices architecture because its modularity
of small, focused, quasi-independent services allow businesses to deploy and
scale services more easily. This segmentation also allows smaller teams that
create smaller code bases.
Microservices also lend themselves to
agile, scrum and continuous delivery
software development processes with shorter lifecycles. This architecture
distinguishes itself from service-oriented architecture (SOA) because each
microservice only belongs to one application, not multiple.
Where Do Microservices Go Amiss and
What Can You Do?
Since they are inherently individual,
microservices bring with them their own set of new issues. Microservices often
experience compatibility issues, as they are built by different teams on top of
different technologies. This can all lead to an unstable environment where
people are building in different directions. To relate these parts, extensive
workarounds may be required, which may actually take longer to fix than if they
were built in a monolith environment.
Thankfully, there are ways to deal
with these problems. Here we cite the experts on their ways to overcome the five most common hurdles to using microservices:
Microservice Challenge #1: Building
Microservices First
Over-eager developers, ready to push
themselves to market, may start out by first building a microservice and find
that it becomes too complex and hard to develop, ultimately making the app
unscalable.
“Being boring is really good. You can
scale a lot with being boring,” Saleh said. “When you move to a microservices
architecture, it comes with this constant tax on your development cycle that’s
going to slow you down from that point on,” like any complexity will do.
With this in mind, Saleh argues that
people should still start with that behemoth app and then extract information
into the smaller microservices once the app is stable.
Of course, with microservices,
individual pieces should have minimal communication with each other, which is
where he suggests creating a gatekeeper so only one service can contact the
database schema at a time. But this brings its own set of problems when the
services and the APIs they are communicating with each have their own language,
which can lead to lock-step deployment, downtime, and worry of a complete crash
upon redeployment.
Saleh offers what he calls the rather
painful solution of semantic versioning guidelines to allow for continual
deployment. French front-end developer Hugo Giraudel offers the best explanation of SemVer, a
three-component system as follows:
▪
X represents a Major Version, for
anything that will probably break the existing API
▪
Y represents a Minor Version, for
implementing a new feature in a backward-compatible way
▪
Z represents a Patch, for fixing bugs
The system helps you clarify the
release of the API or microservice as X.Y.Z, making version 2.1.0 a much larger
change than 1.1.9, which would be allotted for bug fixes. This allows you to catalog
versions, identify patches, and help guide your team’s major and minor version
releases.
Saleh admits record-keeping can be
tedious, but “this is part of the inherent pain of building a microservices
architecture. What you get out of this is you can scale your engineering team
larger [and] you can scale your application much more easily.”
Also Read: How to Spark API Adoption with Good Documentation
Processes
Microservice Challenge #2:
Information Barriers to Productivity
As software manager Richard Clayton wrote about his team’s experience, microservices can put up
artificial barriers to productivity. “We decided to split the backend into
eight separate services, and made the bad decision of assigning services to
people. This reinforced the notion of ownership of specific services by
developers. Because services were owned by people, developers began complaining
of Service A being blocked by tasks on Service B,” he says. “This lack of
concern became a very bad habit; we stopped trying to understand what our peers
were doing even though we were responsible for reviewing their pull requests…
Developers lost sight of system goals in favor of their individual services’
goals.”
Clayton also says that, while
microservices are meant to be built and scaled independently, there’s a strong
desire to share code. “You can either replicate functionality across services
and increase the maintenance burden, or you need to carefully construct shared
libraries and deal with dependency conflicts that may arise.”
Similarly, Selah mentions that though
microservices enable unique technology customized to each element, the
operational hazards of incongruent parts can increase the potential for system
failures, causing strain on a team that isn’t ready to be ripped apart by new
architecture.
How can your team overcome this?
Well, Clayton argues that microservices shouldn’t be the de-facto architecture.
If your team already has communication issues, it’s a sure way to fail. He also
follows Saleh’s advice in recommending that any microservice must be kept
simple, consciously avoiding the natural habit of going granular from the
start. And he recommends that you build your microservice on top of a Platform
as a Service (PaaS) which will enable better communication among microservices,
at least on the back end.
Also Read: Why You Should Build Apps with an API Back-end
Microservice Challenge #3: How Do
Your Services Find Each Other?
You are building, deploying, scaling
and evolving each of these business capabilities separately, but they need to
be able to communicate with each other in order to create logical workflows and
a complete finished product that, from an end-user perspective, is
indistinguishable from the monolithic app.
Saleh says that most often developers
try to hard code the locations into the source code, but a change to the
location of your services requires changes in your code base, which leads to a
string of other problems.
What is a better way to overcome
these challenges in order for one microservice to find another? You have two
options: service discovery protocol or a centralized router. Both require
registration and deregistration, as well as high availability and scalability.
From there, it’s up to you to decide which fits your development lifecycle.
Service discovery allows for an
automatic detection of services offered and directs one service toward the
other, as the router works between the systems. While the service discovery
tells you where things are, the centralized router is actually proxying all the
traffic. The router is built very transparently and exposed externally, but is
much more challenging to build than the discovery service, where you don’t need
to route all the data.
Microservice Challenge #4: How Can
Services Communicate with Each Other?
Since each part works independently,
there is the risk of latency when each piece is brought together. While the
whole point of microservices is that they are able to work independently, they
need to work together, which can be a repeated challenge. Particularly when
many services are making calls to many others, you can have a “dogpile” of
information — when one service goes down while the other connecting
services don’t have any time-out mechanisms, eventually the entire app will
collapse.
Saleh says you can create a circuit
breaker which acts like a discovery service, where one microservice realizes
another is “sick” and notifies the main circuit breaker. From that point on, a
microservice will be able to check the service discovery to determine if the
microservice it is connected to is broken in order to prevent calls being
made to or from said microservice. Saleh recommends setting a “time out” for
about ten minutes.
Microservice Challenge #5:
Decentralized Data Isn’t Always a Positive
Having decentralized data management
sees two sides to the same coin — it allows for teams to work
independently and for the app to scale more quickly, but how each team
quantifies things can become garbled. As Lewis and Fowler put it, “It means that the conceptual model
of the world will differ between systems. This is a common issue when
integrating across a large enterprise — the ‘sales view’ of a
customer will differ from the ‘support view.’ Some things that are called
‘customers’ in the ‘sales view’ may not appear at all in the ‘support view’.”
When data is managed separately, semantics could truly make or break an
update.”
According to Lewis and Fowler, a good
way to overcome this hurdle — which resides among microservices and with
external APIs — is through domain-driven design. DDD divides and
re-bundles complex domains into multiple bounded contexts, which then maps out
the relationship between them.
You can also choose to manage
inconsistencies by using transactions which test the integrity of the
interactions before releasing an update. However, distributed transactions are
notoriously difficult to implement.
Lewis and Fowler say that none of these
fixes are perfect, but “the trade-off is worth it as long as the cost of fixing
mistakes is less than the cost of lost business under greater consistency.”
In Conclusion: Are Microservices
Right for Your App and Team?
Let’s sum up the benefits and drawbacks
of using a microservices architecture instead of the more common monolithic
kind. Then, we’ll let you decide which is right for your app and your team:
How does a microservice outshine a
monolith?
1
It makes your app more scalable with
smaller teams.
2
Enables modularity and is more open
to change in general.
3
Uses a smaller codebase.
What are microservice architecture’s
limitations?
1
It can cause communication problems
among different parts of the app and within your team.
2
It requires increased effort later on
to catalog, test, and fix incompatibilities.
You should still build the monolith before building
the microservices on top of it.
http://www.slideshare.net/durdn/be-a-happier-developer-with-docker-tricks-of-the-trade
7. Fast application mobility, Real repeatability
{kind=link}
8. Great for development team collaboration
{kind=link}
9. Building blocks for your
Micro-services Architecture
{kind=link}
Starcounter and the Future of Micro-Services
In light of the recent micro-services
movement, the inception of a new breed of in-memory technology is a central
component.
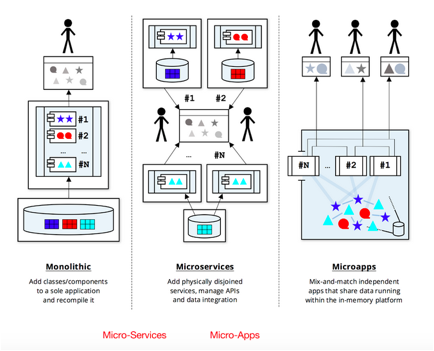
Fig#2: Evolution of the db;
Monolithic, micro-services, & "Starcounter's" micor-apps
http://www.slideshare.net/mstine/microservices-cf-summit
The Impact of Micro-Architectures and APIs on Data Center
Network Design
February
03, 2014 by Lori MacVittie
Application
development trends significantly impact the design of data center networks.
Today there are two trends driving a variety of transformation in the network:
API dominance and micro-architectures. Combined with a tendency for network
operations to protect its critical infrastructure from potentially disruptive
change, these trends are driving toward an emerging "app network"
tier in the data center that is software-defined.
This "app
network" can be realized in one of two ways: through the deployment of
application proxies, or via an application
service fabric. The choice comes
down to how integrated devops and network teams really are, and whether or not
you have a service fabric available. If you do, it's a good solution as it
affords the same flexibility as application proxies while removing
platform-level management from devops shoulders. Only services need be configured,
managed and deployed. An application proxy, too, is a good option and gives
devops and developers complete control over the platform and the network-hosted
domain services.
Today we're going to
dive into the application proxy-based architecture.
APPLICATION PROXY
ARCHITECTURE
Application
proxies are highly
programmable, scalable and perform with the alacrity expected of a
"network" element.
Application proxies
provide devops and developers with the mean to rapidly provision domain
services specific to a micro-service or API. By decomposing traditional
ADC-hosted services into domain specific, application proxy-hosted services,
each service can be containerized and their deployment subsequently automated
to ensure CPR (consistent, predictable and repeatable) results. Successful continuous
delivery is the end goal. As noted earlier, this can be achieved via an
application services fabric as well as dedicated application proxies.
This architectural
model is more efficient in terms of resource consumption. Decomposing services
ensures they scale independently. When services are code-level integrated into
applications, the overall application footprint is much larger and requires
more storage and more compute to scale. Decomposition reduces demand for
storage and compute overall by only requiring expansion of a subset of services
at any given time.
When the application
proxy is highly programmable, devops and developers receive added benefits in
the form of being able to codify services and treat as part of the code base
rather than as separation configuration files. For example, specifying simple
URI rewrite rules in some proxies requires changes to a configuration file.
Using a programmable application proxy, such rules are coded and treated like
artifacts; they can leverage existing build systems like Jenkins. They became
part of the overall application rather than separate configuration files that
must be merged, replaced, or otherwise managed. Using programmatic means to
implement domain specific services affords devops more opportunity to
seamlessly integrate with existing application deployment processes and
increase its success rates.
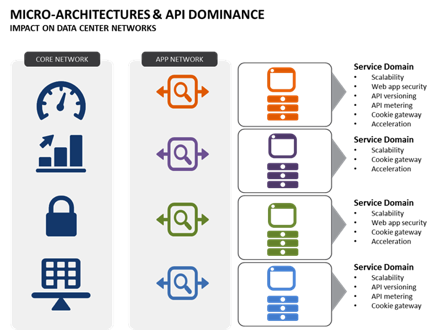
The transformation
of application architectures is driving data center networks toward a need for
programmable domain services. These services must match service velocity and change the economy of
scale as the number of
applications needing services increases with each new application and
application version. Not doing so means organizations will respond with
discrete services that introduce operational risk and inability to consistently
deploy new applications.
Both application
proxies and application service fabrics meet these requirements, and both
models are equally capable in offering a more seamless, less disconnected
continuous delivery experience.
last modified:
November 26, 2013
https://www.nginx.com/blog/introduction-to-microservices/
Chris Richardson 5/19/2015
Microservices are currently getting a
lot of attention: articles, blogs, discussions on social media, and conference
presentations. They are rapidly heading towards the peak of inflated
expectations on the Gartner Hype cycle. At the same time, there are skeptics in the software community
who dismiss microservices as nothing new. Naysayers claim that the idea is just
a rebranding of SOA. However, despite both the hype and the skepticism, the Microservice
architecture pattern has significant benefits –
especially when it comes to enabling the agile development and delivery of
complex enterprise applications.
This blog post is the first in a
7-part series about designing, building, and deploying microservices. You will
learn about the approach and how it compares to the more traditional Monolithic architecture pattern. This series will describe the various elements of the
Microservice architecture. You will learn about the benefits and drawbacks of
the Microservice architecture pattern, whether it makes sense for your project,
and how to apply it.
[Editor: Further posts in this series
are now available:
▪
Building Microservices:
Using an API Gateway
▪
Building Microservices:
Inter-Process Communication in a Microservices Architecture
▪
Service Discovery in a
Microservices Architecture]
Let’s first look at why you should
consider using microservices.
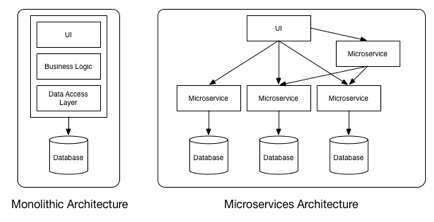
Building Monolithic Applications
Let’s imagine that you were starting
to build a brand new taxi-hailing application intended to compete with Uber and
Hailo. After some preliminary meetings and requirements gathering, you would
create a new project either manually or by using a generator that comes with
Rails, Spring Boot, Play, or Maven. This new application would have a modular hexagonal architecture, like in the following diagram:
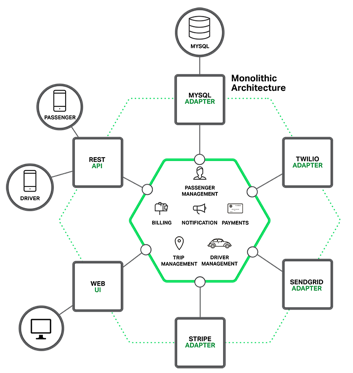
At the core of the application is the
business logic, which is implemented by modules that define services, domain
objects, and events. Surrounding the core are adapters that interface with the
external world. Examples of adapters include database access components,
messaging components that produce and consume messages, and web components that
either expose APIs or implement a UI.
Despite having a logically modular
architecture, the application is packaged and deployed as a monolith. The
actual format depends on the application’s language and framework. For example,
many Java applications are packaged as WAR files and deployed on application
servers such as Tomcat or Jetty. Other Java applications are packaged as
self-contained executable JARs. Similarly, Rails and Node.js applications are
packaged as a directory hierarchy.
Applications written in this style
are extremely common. They are simple to develop since our IDEs and other tools
are focused on building a single application. These kinds of applications are
also simple to test. You can implement end-to-end testing by simply launching
the application and testing the UI with Selenium. Monolithic applications are
also simple to deploy. You just have to copy the packaged application to a
server. You can also scale the application by running multiple copies behind a
load balancer. In the early stages of the project it works well.
Marching Towards Monolithic Hell
Unfortunately, this simple approach
has a huge limitation. Successful applications have a habit of growing over
time and eventually becoming huge. During each sprint, your development team
implements a few more stories, which, of course, means adding many lines of
code. After a few years, your small, simple application will have grown into a monstrous monolith. To give an
extreme example, I recently spoke to a developer who was writing a tool to
analyze the dependencies between the thousands of JARs in their multi-million
line of code (LOC) application. I’m sure it took the concerted effort of a
large number of developers over many years to create such a beast.
Once your application has become a
large, complex monolith, your development organization is probably in a world
of pain. Any attempts at agile development and delivery will flounder. One
major problem is that the application is overwhelmingly complex. It’s simply
too large for any single developer to fully understand. As a result, fixing
bugs and implementing new features correctly becomes difficult and time
consuming. What’s more, this tends to be a downwards spiral. If the codebase is
difficult to understand, then changes won’t be made correctly. You will end up
with a monstrous, incomprehensible big ball of mud.
The sheer size of the application
will also slow down development. The larger the application, the longer the
start-up time is. For example, in a recent survey some developers reported start-up times as long as 12 minutes.
I’ve also heard anecdotes of applications taking as long as 40 minutes to start
up. If developers regularly have to restart the application server, then a
large part of their day will be spent waiting around and their productivity
will suffer.
Another problem with a large, complex
monolithic application is that it is an obstacle to continuous deployment.
Today, the state of the art for SaaS applications is to push changes into
production many times a day. This is extremely difficult to do with a complex
monolith since you must redeploy the entire application in order to update any
one part of it. The lengthy start-up times that I mentioned earlier won’t help
either. Also, since the impact of a change is usually not very well understood,
it is likely that you have to do extensive manual testing. Consequently,
continuous deployment is next to impossible to do.
Monolithic applications can also be
difficult to scale when different modules have conflicting resource
requirements. For example, one module might implement CPU-intensive image
processing logic and would ideally be deployed in Amazon EC2 Compute Optimized
instances. Another module might be an in-memory database and best
suited for EC2 Memory-optimized
instances. However, because these modules are deployed together you
have to compromise on the choice of hardware.
Another problem with monolithic
applications is reliability. Because all modules are running within the same
process, a bug in any module, such as a memory leak, can potentially bring down
the entire process. Moreover, since all instances of the application are
identical, that bug will impact the availability of the entire application.
Last but not least, monolithic
applications make it extremely difficult to adopt new frameworks and languages.
For example, let’s imagine that you have 2 million lines of code written using
the XYZ framework. It would be extremely expensive (in both time and cost) to
rewrite the entire application to use the newer ABC framework, even if that
framework was considerably better. As a result, there is a huge barrier to
adopting new technologies. You are stuck with whatever technology choices you
made at the start of the project.
To summarize: you have a successful
business-critical application that has grown into a monstrous monolith that
very few, if any, developers understand. It is written using obsolete,
unproductive technology that makes hiring talented developers difficult. The
application is difficult to scale and is unreliable. As a result, agile
development and delivery of applications is impossible.
So what can you do about it?
Microservices – Tackling
the Complexity
Many organizations, such as Amazon,
eBay, and Netflix, have solved this problem by adopting what is now known as the Microservice
architecture pattern. Instead of building a single
monstrous, monolithic application, the idea is to split your application into
set of smaller, interconnected services.
A service typically implements a set
of distinct features or functionality, such as order management, customer
management, etc. Each microservice is a mini-application that has its own
hexagonal architecture consisting of business logic along with various
adapters. Some microservices would expose an API that’s consumed by other
microservices or by the application’s clients. Other microservices might
implement a web UI. At runtime, each instance is often a cloud VM or a Docker
container.
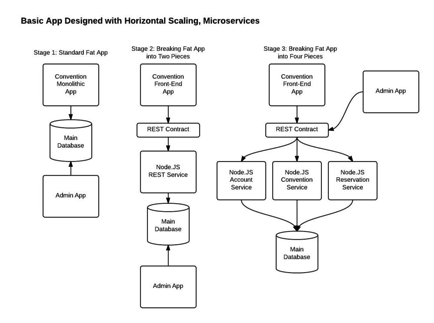
For example, a possible decomposition
of the system described earlier is shown in the following diagram:
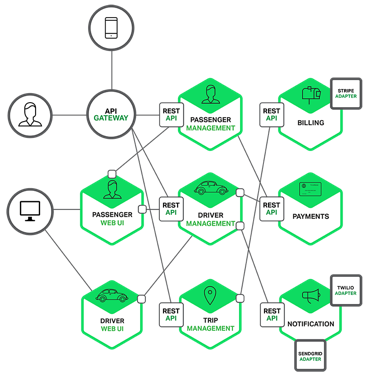
Each functional area of the
application is now implemented by its own microservice. Moreover, the web
application is split into a set of simpler web applications (such as one for
passengers and one for drivers in our taxi-hailing example). This makes it
easier to deploy distinct experiences for specific users, devices, or
specialized use cases.
Each back-end service exposes a REST
API and most services consume APIs provided by other services. For example,
Driver Management uses the Notification server to tell an available driver
about a potential trip. The UI services invoke the other services in order to
render web pages. Services might also use asynchronous, message-based
communication. Inter-service communication will be covered in more detail later
in this series.
Some REST APIs are also exposed to
the mobile apps used by the drivers and passengers. The apps don’t, however,
have direct access to the back-end services. Instead, communication is mediated
by an intermediary known as an API Gateway. The API Gateway
is responsible for tasks such as load balancing, caching, access control, API
metering, and monitoring, and can be implemented effectively using NGINX. Later articles in the series will cover the API Gateway.
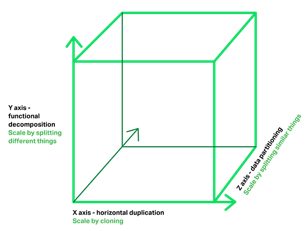
The Microservice architecture pattern
corresponds to the Y-axis scaling of the Scale Cube, which is a
3D model of scalability from the excellent book The Art of Scalability. The other two scaling axes are X-axis scaling, which consists
of running multiple identical copies of the application behind a load balancer,
and Z-axis scaling (or data partitioning), where an attribute of the request
(for example, the primary key of a row or identity of a customer) is used to
route the request to a particular server.
Applications typically use the three
types of scaling together. Y-axis scaling decomposes the application into
microservices as shown above in the first figure in this section. At runtime,
X-axis scaling runs multiple instances of each service behind a load balancer
for throughput and availability. Some applications might also use Z-axis
scaling to partition the services. The following diagram shows how the Trip Management
service might be deployed with Docker running on Amazon EC2.
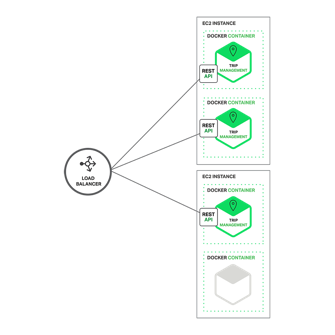
At runtime, the Trip Management
service consists of multiple service instances. Each service instance is a
Docker container. In order to be highly available, the containers are running
on multiple Cloud VMs. In front of the service instances is a load balancer such as NGINX that distributes requests across the instances. The load
balancer might also handle other concerns such as caching, access control, API metering, and monitoring.
The Microservice architecture pattern
significantly impacts the relationship between the application and the
database. Rather than sharing a single database schema with other services,
each service has its own database schema. On the one hand, this approach is at
odds with the idea of an enterprise-wide data model. Also, it often results in
duplication of some data. However, having a database schema per service is essential
if you want to benefit from microservices, because it ensures loose coupling.
The following diagram shows the database architecture for the example
application.
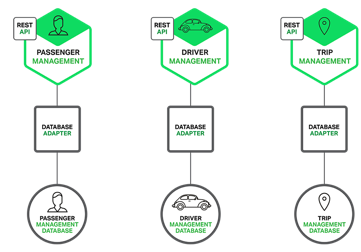
Each of the services has its own
database. Moreover, a service can use a type of database that is best suited to
its needs, the so-called polyglot persistence architecture. For example, Driver
Management, which finds drivers close to a potential passenger, must use a
database that supports efficient geo-queries.
On the surface, the Microservice
architecture pattern is similar to SOA. With both approaches, the architecture
consists of a set of services. However, one way to think about the Microservice
architecture pattern is that it’s SOA without the commercialization and
perceived baggage of web service
specifications (WS-*) and an Enterprise Service Bus
(ESB). Microservice-based applications favor simpler, lightweight protocols
such as REST, rather than WS-*. They also very much avoid using ESBs and
instead implement ESB-like functionality in the microservices themselves. The
Microservice architecture pattern also rejects other parts of SOA, such as the
concept of a canonical schema.
The Benefits of Microservices
The Microservice architecture pattern
has a number of important benefits.
First, it tackles
the problem of complexity. It decomposes what would otherwise be a monstrous
monolithic application into a set of services. While the total amount of
functionality is unchanged, the application has been broken up into manageable
chunks or services. Each service has a well-defined boundary in the form of an
RPC- or message-driven API. The Microservice architecture pattern enforces a
level of modularity that in practice is extremely difficult to achieve with a
monolithic code base. Consequently, individual services are much faster to
develop, and much easier to understand and maintain.
Second, this
architecture enables each service to be developed independently by a team that
is focused on that service. The developers are free to choose whatever
technologies make sense, provided that the service honors the API contract. Of
course, most organizations would want to avoid complete anarchy and limit
technology options. However, this freedom means that developers are no longer
obligated to use the possibly obsolete technologies that existed at the start
of a new project. When writing a new service, they have the option of using
current technology. Moreover, since services are relatively small it becomes
feasible to rewrite an old service using current technology.
Third, the
Microservice architecture pattern enables each microservice to be deployed
independently. Developers never need to coordinate the deployment of changes
that are local to their service. These kinds of changes can be deployed as soon
as they have been tested. The UI team can, for example, perform A|B testing and
rapidly iterate on UI changes. The Microservice architecture pattern makes
continuous deployment possible.
Finally, the
Microservice architecture pattern enables each service to be scaled
independently. You can deploy just the number of instances of each service that
satisfy its capacity and availability constraints. Moreover, you can use the
hardware that best matches a service’s resource requirements. For example, you
can deploy a CPU-intensive image processing service on EC2 Compute Optimized
instances and deploy an in-memory database service on EC2 Memory-optimized
instances.
The Drawbacks of Microservices
As Fred Brooks wrote almost 30 years
ago, there are no silver bullets. Like every other technology, the Microservice
architecture has drawbacks. One drawback is the name itself. The term microservice
places excessive emphasis on service size. In fact, there are some developers who advocate for building
extremely fine-grained 10-100 LOC services. While small services are
preferable, it’s important to remember that they are a means to an end and not
the primary goal. The goal of microservices is to sufficiently decompose the
application in order to facilitate agile application development and
deployment.
Another major drawback of
microservices is the complexity that arises from the fact that a microservices
application is a distributed system. Developers need to choose and implement an inter-process
communication mechanism based on either messaging or RPC. Moreover, they must
also write code to handle partial failure since the destination of a request
might be slow or unavailable. While none of this is rocket science, it’s much
more complex than in a monolithic application where modules invoke one another
via language-level method/procedure calls.
Another challenge with microservices
is the partitioned database architecture. Business transactions that update multiple business entities
are fairly common. These kinds of transactions are trivial to implement in a
monolithic application because there is a single database. In a
microservices-based application, however, you need to update multiple databases
owned by different services. Using distributed transactions is usually not an
option, and not only because of the CAP theorem. They simply are
not supported by many of today’s highly scalable NoSQL databases and messaging
brokers. You end up having to use an eventual consistency based approach, which
is more challenging for developers.
Testing a microservices application
is also much more complex. For example, with a modern
framework such as Spring Boot it is trivial to write a test class that starts
up a monolithic web application and tests its REST API. In contrast, a similar
test class for a service would need to launch that service and any services
that it depends upon (or at least configure stubs for those services). Once
again, this is not rocket science but it’s important to not underestimate the
complexity of doing this.
Another major challenge with the
Microservice architecture pattern is implementing
changes that span multiple services. For example,
let’s imagine that you are implementing a story that requires changes to
services A, B, and C, where A depends upon B and B depends upon C. In a
monolithic application you could simply change the corresponding modules,
integrate the changes, and deploy them in one go. In contrast, in a
Microservice architecture pattern you need to carefully plan and coordinate the
rollout of changes to each of the services. For example, you would need to
update service C, followed by service B, and then finally service A.
Fortunately, most changes typically impact only one service and multi-service
changes that require coordination are relatively rare.
Deploying a microservices-based
application is also much more complex. A monolithic
application is simply deployed on a set of identical servers behind a
traditional load balancer. Each application instance is configured with the
locations (host and ports) of infrastructure services such as the database and
a message broker. In contrast, a microservice application typically consists of
a large number of services. For example, Hailo has 160 different
services and Netflix has over 600 according to Adrian Cockcroft. Each service will have
multiple runtime instances. That’s many more moving parts that need to be
configured, deployed, scaled, and monitored. In addition, you will also need to
implement a service discovery mechanism (discussed in a later post) that
enables a service to discover the locations (hosts and ports) of any other
services it needs to communicate with. Traditional trouble ticket-based and
manual approaches to operations cannot scale to this level of complexity.
Consequently, successfully deploying a microservices application requires
greater control of deployment methods by developers, and a high level of
automation.
One approach to automation is to use
an off-the-shelf PaaS such as Cloud Foundry. A PaaS provides developers with an easy way to deploy and
manage their microservices. It insulates them from concerns such as procuring
and configuring IT resources. At the same time, the systems and network
professionals who configure the PaaS can ensure compliance with best practices
and with company policies. Another way to automate the deployment of
microservices is to develop what is essentially your own PaaS. One typical
starting point is to use a clustering solution, such as Mesos or Kubernetes in conjunction with a technology
such as Docker. Later in this series we will look at how software-based application delivery approaches
like NGINX, which easily handles caching, access control, API metering, and
monitoring at the microservice level, can help solve this problem.
Summary
Building complex applications is
inherently difficult. A Monolithic architecture only makes sense for simple,
lightweight applications. You will end up in a world of pain if you use it for
complex applications. The Microservice architecture pattern is the better
choice for complex, evolving applications despite the drawbacks and
implementation challenges.
In later blog posts, I’ll dive into
the details of various aspects of the Microservice architecture pattern and
discuss topics such as service discovery, service deployment options, and
strategies for refactoring a monolithic application into services.
Stay tuned…
[Editor: Further posts in this 7-part
series are now available:
▪
Building Microservices:
Using an API Gateway
▪
Building Microservices:
Inter-Process Communication in a Microservices Architecture]
Guest blogger Chris Richardson is the founder of the original
CloudFoundry.com, an early Java PaaS (Platform-as-a-Service) for Amazon EC2. He
now consults with organizations to improve how they develop and deploy
applications. He also blogs regularly about microservices at http://microservices.io.
http://benjchristensen.com
given
user experience, requiring client applications to make multiple calls that need
to be assembled in order to render a single user experience. This interaction
model is illustrated in the following diagram:
http://www.infoq.com/news/2015/06/taming-dependency-hell
Taming Dependency Hell within
Microservices with Michael Bryzek
by
Daniel Bryant on Jun 13, 2015
Michael Bryzek, co-founder and ex-CTO at Gilt, discussed at QCon New York how ‘dependency hell’ could impact
the delivery and maintenance of microservice platforms. Bryzek suggested that
dependency hell may be mitigated by making API design ‘first class’,
ensuring backward and forward compatibility, providing accurate documentation,
and generating client libraries.
Quoting
the Wikipedia entry for dependency hell,
Bryzek introduced the phrase to the audience and suggested that almost every
developer has witnessed this at some point in their career:
Dependency
hell is a colloquial term for the frustration of some software users who have installed
software packages which have dependencies on specific versions of other
software packages
Bryzek
discussed how Gilt.com, a
luxury brand flash sales ecommerce site, moved from a traditional Ruby on Rails
monolithic stack to a Scala-based microservice platform over the course of five years.
This, combined with the growth of the technical team to over 150 people, lead
the team to ask how dependencies should be managed, specifically dependencies
that were used in libraries.
Four
strategies for minimising the pain associated with dependency management were
presented:
▪ API design must be first class
▪ Backward and forward compatibility
▪ Accurate documentation
▪ Generated client libraries
Bryzek
proposed that several of these strategies can be implemented with appropriate
tooling, and accordingly he has created a Scala-based tool named apidoc for this purpose. apidoc has no
external dependencies on an existing software process nor runtime, and is open
source and provided as a free to use software as a
service (SaaS).
Bryzek commented that over 100 services have already been built at Gilt with
apidoc.
Diving
into each of the strategies mentioned above, Bryzek proposed that the design of
an API and the associated data structures are often the hardest things to
change within a system. Therefore, they should be designed up-front, and the
corresponding artefacts integrated into the design process to ensure accuracy
between a service and associated clients. This is in essence, “schema first
design”.
In
regards to ensuring backwards compatibility of an API or client library, Bryzek
suggested that developers should imagine processing historical records whenever
a change to an API is made. Fields added to an API should either be optional or
have sensible defaults, and renaming of fields should never occur - instead new
models should be introduced, and a migration path be provided where
appropriate.
Forwards
compatibility is also an important concern, and for this scenario developers
should imagine processing new messages arriving to the service with new data.
The benefits of Postel’s law, ‘be conservative in what you do, be liberal in
what you accept from others’ are relevant to this discussion. APIs (and
corresponding client libraries) should be versioned to aid developers, and one
such technique for versioning is semantic versioning.
Additional
considerations for establishing forwards compatibility include being
careful when using enums, for example when using binary interface
definition languages such as Apache Avro or Apache Thrift, and being careful when throwing errors if an unknown field
is encountered within an API’s data structure. Ideally tooling should clearly
indicate when things have changed within an API or client library, and the
apidoc tool provides this functionality.
Accurate
documentation for an API is also essential, and this may be automatically
generated, for example using a tool such as Swagger 2.0. Bryzek also discussed that
although he was initially sceptical, he now believes that generating client
libraries automatically from an API can be beneficial. For example, boilerplate
API consumption code can be removed (or encapsulated within the client
library), and consistent naming for fields and actions can be maintained
across services. However, care should be taken to ensure that the client
library has minimal external dependencies (so that the dependency hell is not
pushed down into the stack), and generating a client that developers will enjoy
using can be very challenging.
Additional
details about Michael Bryzek’s “Microservices and the art of taming the Dependency Hell
Monster” talk can
be found on the QCon New York 2015 website, and more information about the apidoc tool can be found on the project’s
Github website and the Gilt Tech blog.
https://developer.ibm.com/bluemix/2015/01/19/microservices-bluemix/
Microservices in
Bluemix
amqp Bluemix microservices mq mqlight MQTT node.js websockets
|
|
JEFF
SLOYER / JANUARY 19, 2015 / 2
COMMENTS |
Monolith apps are no
more. The age of the monolith is over. It wasn’t that long ago that
companies and developers (myself included) were deploying one giant app that
did everything. The app would serve all your static files, front-end HTML
and CSS and Javascript, act as your REST API, serve as your data persistance
tier, handles sessions, handle logins, and do security for your app. The
list could keep going on and on. As the age of the code base progresses
it gets more and more complicated and tangled and if a new feature needs to be
developed or an old piece of code needs to be modified it takes a cross
functional team of many different people to make it happen.
First we are going
to talk about how a monolith app works, some of the positives and negatives and
then we will talk about how things work in an app utilizing microserivces and
the positivities and negatives associated with it.
...
http://www.bigdatalittlegeek.com/architectural-diagrams/
http://www.sec.gov/Archives/edgar/data/1301031/000119312511189260/ds1.htm
http://martinfowler.com/microservices/
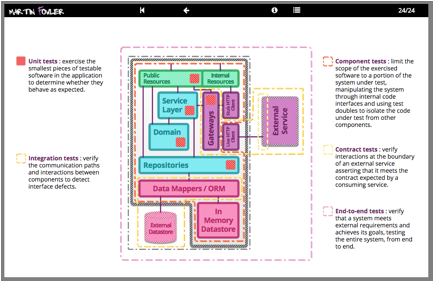
oby
Clemson put together an infodeck that examines testing when building a
microservices systems: the various kinds of tests to consider, and how various
...
http://www.redbooks.ibm.com/redpapers/pdfs/redp5271.pdf
Creating Applications in
Bluemix Using the Microservices Approach
Gucer Vasfi
Shishir Narain
http://softwareengineeringdaily.com/2015/07/15/nodejs-and-the-distinction-between-microservices-and-soa/
http://www.cakesolutions.net/teamblogs/microservice-architecture-framework
Microservice Architectures: A Framework for Implementation and Deployment
Posted by Carl Pulley
Sat, Dec 20, 2014
Microservice
Architectures
Microservice architectures
have become popular in recent years as they offer the opportunity to modularly
and elastically scale applications. They achieve this by decomposing an
applications functionality into a decoupled and discrete set of microservices.
As a result, the number of microservice instances that are active at any point
in time may be elastically scaled (up or down) according to factors such as
demand and availability.
A microservice
architecture displays the following characteristics:
▪ set of collaborating (micro)services, each of which implements a
limited set of related functionality (there is typically no central control)
▪ microservices communicate with each other asynchronously over
the network (i.e. decoupled application) using language agnostic APIs (e.g.
REST)
▪ microservices are developed and deployed independently of each
other
▪ microservices use their own persistent storage area (c.f.
sharding) with data consistency maintained using data replication or
application level events.
However, care needs to be
exercised when decomposing an application into microservices, since it can be
all too easy to refactor application complexity elsewhere!
Microservice
Implementation Overview
In this post, I present
and discuss a framework within which one may:
▪ implement microservice architectures based upon Akka clustering
and persistence
▪ provision, deploy and control such distributed applications into
cloud based infrastructures (e.g. AWS or Rackspace clouds).
https://www.opencredo.com/2014/11/19/7-deadly-sins-of-microservices/
19 November, 2014
Undeniably, there is a
growing interest in microservices as we see more organisations, big and small,
evaluating and implementing this emerging approach. Despite its apparent
novelty, most concepts and principles underpinning microservices are not
exactly new – they are simply proven and commonsense software development
practices that now need to be applied holistically and at a wider scale, rather
than at the scale of a single program or machine. These principles include
separation of concerns, loose coupling, scalability and fault-tolerance.
However, given the lack of
a precise and universal definition for microservices, it becomes clear that
there is no single recipe for implementing a microservices system successfully.
Additionally, certain
engineering practices that can be essential to a viable microservices
implementation, such as continuous delivery and configuration management, are frequently
perceived as optional add-ons, whereas they should be considered an integral
part of a microservices architecture.
Thus understanding how to
approach microservices remains a challenge; but equally important, how not to
approach microservices.
We encountered a number of
anti-patterns on a number of projects we worked on, building systems that can
be characterised as ‘microservices’. Given their pervasive nature, they should
be considered and understood, ideally in the early stages of a project, in
order to be mitigated and avoided. Those are:
1. Building the wrong
thing
Given the lack of
specificity surrounding microservices, we can easily but mistakenly assume that
every stakeholder in the project’s team on a new microservices implementation
share the same vision, goals and expectations. In practice, it is not that
obvious.
Similarly, it is easy to
overestimate the level of sophistication and flexibility that need to be
provided by a given microservices implementation in terms what features are offered
and what languages, platforms and supported.
The risk in this case is
to invest time and effort into activities that turn out to be inessential. Lack
of clarity in the goals and scope of the project can therefore lead to
increased complexity and loss of focus in the development effort.
What you should do
instead: Questions about what
actually needs to be built should be explicitly addressed during the early
phases of the project e.g. who is going to develop and maintain the new
services? Who are the principal users of the system? What languages, platforms
and technologies do we need to support? What tools will developers need to
create and deploy new services?
It is essential to be
explicit about the goals of the project but also about the non-goals in order
to avoid unneeded complexity being introduced into the project.
2. Failing to adopt a
contract-first design approach
A microservices
architecture facilitates manipulating services individually to achieve
operational flexibility, scalability and fault-tolerance. Nevertheless,
building useful applications is essentially achieved by composing multiple
services in meaningful ways.
In this context, a well
defined service contract plays a number of essential roles:
▪ Abstraction: a service contract allows us to think in terms of
what a service does as opposed to how it is implemented.
▪ Encapsulation: contracts hide away implementation details hence
reducing tight coupling between services and consumers. A good contract also
facilitates evolution in a controlled way by maintaining a clear separation
between the intent of the service and its implementation.
▪ Composition: services have to be composed in order to be useful,
at least through simple invocation from a single consumer. As the system
evolves, services end up being used and composed a variety of new ways.
One common pitfall when
implementing a service is focusing primarily on the implementation at the
expense of the service’s contract. If the a service’s API (contract) is not
well thought out, there is a risk that we expose internal implementation
details to consumers, making the service hard to consume and to evolve when new
requirements arise.
What you should do
instead: Avoid contracts that
are generated automatically and that are likely to expose internal application
structures. Start working on each new service by defining its contract first. A
resource-oriented approach to service design can help in building simple
service that can evolve well when required.
3. Assuming the wrong
communication protocols
It is quite common for
microservices to make use of simple communication protocols, such as http, or
in some cases lightweight message brokers, to communicate. Messages exchanged
can be encoded in a variety of ways, from human-readable formats (JSON, YAML),
to serialised binary objects.
It goes without saying
that each approach has its pros and cons and
that we need to understand
what communication patterns, features and guarantees we need to support in
order to choose the right approach and toolset.
Less obvious though is
that this choice does not need to be restricted to a single protocol or
approach across the whole system; there are situations where mixing different
communication styles and protocols is needed and justified.
What you should do
instead: Avoid committing to
any communication protocol before getting a good understanding of the
capabilities of service consumers you need to support. One useful distinction
to make is between external and internal services. External services often need
to provide an http interface to be widely accessible, while internal services
can sometimes benefit from richer capabilities provided by message brokers for
example.
4. Introducing a shared
domain model
In a traditional
monolithic architecture, it is fairly common to create a centralised domain
model, that is then used to implement all sort of functionality from input
validation, to business logic and persisting business entities to the database.
The fundamental assumption
behind a shared domain model is that one application is providing the full
boundaries and context within which the domain model is valid. Therefore
sharing the same domain model is in this context is safe and has clear
advantages.
In a microservices
architecture, things are very different. An application is no more one single
entity with rigidly defined boundaries; it is instead an aggregation of a
number of any number of services that should be loosely coupled and
independent. Sharing the same domain across services creates tight coupling and
should be considered as a potential indication that one logical service is
being split across a number of deployable units.
From an operational
perspective, sharing a single domain creates dependencies between components
that are otherwise independent through sharing of common binary artefacts.
Every minor update to the shared domain model will require every services that
depends on it to be updated and redeployed, that is if we truly wish to
maintain a single shared domain. At scale, this can cause real operational
challenges.
What you should do
instead: To maintain
encapsulation and separation of concerns, each service should have its own
domain, that it is able evolve independently from other services. The domain of
an application should be expressed through service interaction, not through a
shared object model.
Avoid creating shared
dependencies on artefacts that are under constant pressure to evolve such as
the domain model.
5. Defining inappropriate
service boundaries
Another common issue
resulting from applying familiar development practices indiscriminately to a
microservices architecture is to create new services directly from internal
application components without considering carefully the boundaries of each
service.
Internal components, even
with a well-defined interface, do not always make good standalone services:
business-tier services can have inter-dependencies or can expose operations at
a granularity that is awkward for remote invocation. Other internal components,
such as data repositories, are often too technical and do not expose business
operations that are self-contained and meaningful to the business domain.
The risk in this situation
is that you might build a so-called distributed monolith, which is an
application with a monolithic architecture but that is also required to deal
with issues related to remote service invocation such as latency and cascading
failures.
What you should do
instead: Design services that are
truly self-contained and independent. In a microservices architecture, service
boundaries should enforce separation of concerns at a business level, as
opposed to separation of concerns along technical layers, which is common for
monolithic applications.
6. Neglecting DevOps and
Testing Concerns
One of the appeals of
microservices is to develop, build and deploy small and simple parts of the
system, that is services, individually and independently from each other. As we
add more services and combine them in different ways, the complexity of the
system inevitably increases. At some point, it becomes impractical to manage
the system in an ad-hoc way, while maintaining speed of development and
stability at the same time.
Achieving a high level of
automation efficiency though is not everything; we need to guarantee that the
system remains sound and functional after each small change is implemented,
including changes coming potentially from other parts of the business, for
example another team located in a different country.
Failing to implement
serious DevOps and automated testing practices from the start will produce a
system that is brittle, unwieldy and ultimately unviable.
What you should do
instead: Introduce proven
DevOps practices, such as continuous delivery and configuration management from
the start. A continuous delivery pipeline should be an integral part of a
microservices implementation, reducing engineering complexities handled
traditionally by the services themselves.
Automate acceptance,
regression and performance testing at an early stage as well. The hardest thing
in a microservices architecture is not testing services individually – it
is rather making sure that the whole system remains functional and coherent
after every change.
7. Disregarding the Human
Factor
While microservices can
bring simplicity and focus to the development process, the flip side of the
coin is that developers are required to increase their understanding of the
bigger picture and to have deeper understanding of software engineering
concepts related to how services behave and interact at runtime. These include
remote invocation, scalability and fault-tolerance. These skills, whilst always
essential, were not traditionally seen as must-haves for developers working on
run-of-the-mill enterprise applications.
Unsurprisingly, developers
who lack good familiarity these concepts and techniques are very likely to hit
a number of pitfalls when first confronted with a microservices system.
At a higher scale,
organisations where silos are rife and where collaboration is impeded by
political obstacles are unlikely to benefit from a microservices approach that
primarily relies on wide-scale collaboration between all stakeholders to be
successful.
Under the circumstances
adopting a microservices architecture can backfire and result in a complex and
inefficient system that will fail to deliver on its promise.
What you should do
instead: Microservices are
not a silver bullet. Invest in your developers and encourage collaboration
across the organisation to build systems that are sustainable and evolvable.
https://virtualizationreview.com/articles/2014/10/29/containers-virtual-machines-and-docker.aspx
Are Containers the Beginning of the End of Virtual
Machines?
As Docker rises in importance, the idea of the
traditional VM is being challenged.
By Jeffrey Schwartz10/29/2014
Containers are frequently described as lightweight
runtime environments with many of the core components of a VM and isolated
services of an OS designed to package and execute these micro-services. While
containers have long existed as extensions to Linux distributions (there are no
native Windows commercial containers yet), each has come with its own flavor.
The rise of open source Docker containers over the
past year has created a de-facto standard for how applications can extend from
one platform to another running as micro-services in Linux server and OpenShift
PaaS environments such as Cloud Foundry. Docker containers have recently become
available with major Linux distributions and are supported in key cloud
services. Similarly, Microsoft's longstanding effort to develop its own native
Windows containers, code-named "Drawbridge," is poised to come out of
incubation. And at press time, Docker Inc., a Silicon Valley startup formed in
2012, and Microsoft announced a deep partnership that will result in
Docker containers running in the Microsoft Azure public cloud and in the next
version of Windows Server.
Over the past year, Docker has risen from obscurity to potentially one
of the fastest-rising new players in the world of enterprise application and
infrastructure software. In many ways, Docker and similar lightweight
containers promise to transform the role of the OS and the VM much like the VM
has done to the physical bare-metal server environment. That's because in order
for emerging Platform-as-a-Service (PaaS) clouds to scale and software to
interoperate, there's too much overhead in today's VMs, particularly when more
are needed than is feasible for specific services.
https://www.microsoftpressstore.com/articles/article.aspx?p=2248811&seqNum=3
Discovering the Domain
Architecture
▪
By Dino Esposito and Andrea Saltarello
▪
9/10/2014
Bounded contexts
In the beginning, you assume one indivisible business domain and start processing
requirements to learn as much as possible about it and build the ubiquitous
language. As you proceed, you learn how the organization works, which processes
are performed, how data is used and, last but not least, you learn how things
are referred to.
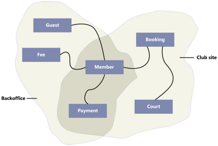
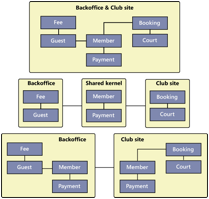
http://vasters.com/clemensv/2012/09/01/Sagas.aspx
The picture shows a simple Saga. If you book a
travel itinerary, you want a car and a hotel and a flight. If you can't get all
of them, it's probably not worth going. It's also very certain that you can't
enlist all of these providers into a distributed ACID transaction. Instead,
you'll have an activity for booking rental cars that knows both how to perform
a reservation and also how to cancel it - and one for a hotel and one for
flights.
https://www.nginx.com/blog/building-microservices-using-an-api-gateway/
Chris Richardson · June 15, 2015
Building Microservices: Using an API
Gateway
.entry-header
The first article in this
7-part series about designing, building, and deploying microservices introduced the Microservice Architecture pattern. It discussed
the benefits and drawbacks of using microservices and how, despite the
complexity of microservices, they are usually the ideal choice for complex
applications. This is the second article in the series and will discuss
building microservices using an API Gateway.
[Editor: Further posts in this series
are now available:
▪
Building Microservices:
Inter-Process Communication in a Microservices Architecture
▪
Service Discovery in a
Microservices Architecture]
When you choose to build your
application as a set of microservices, you need to decide how your
application’s clients will interact with the microservices. With a monolithic
application there is just one set of (typically replicated, load-balanced)
endpoints. In a microservices architecture, however, each microservice exposes
a set of what are typically fine-grained endpoints. In this article, we examine
how this impacts client-to-application communication and proposes an approach
that uses an API Gateway.
Introduction
Let’s imagine that you are developing
a native mobile client for a shopping application. It’s likely that you need to
implement a product details page, which displays information about any given
product.
For example, the following diagram
shows what you will see when scrolling through the product details in Amazon’s
Android mobile application.
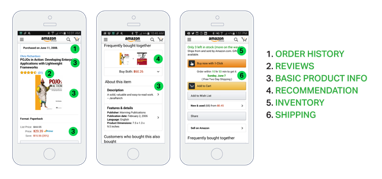
Even though this is a smartphone
application, the product details page displays a lot of information. For
example, not only is there basic product information (such as name,
description, and price) but this page also shows:
▪
Number of items in the shopping cart
▪
Order history
▪
Customer reviews
▪
Low inventory warning
▪
Shipping options
▪
Various recommendations, including
other products this product is frequently bought with, other products bought by
customers who bought this product, and other products viewed by customers who
bought this product
▪
Alternative purchasing options
When using a monolithic application
architecture, a mobile client would retrieve this data by making a single REST
call (GET api.company.com/productdetails/productId) to the application.
A load balancer routes the request to one of N identical application instances.
The application would then query various database tables and return the
response to the client.
In contrast, when using the
microservice architecture the data displayed on the product details page is
owned by multiple microservices. Here are some of the potential microservices
that own data displayed on the example product details page:
4
Shopping Cart
Service – Number of items in the shopping cart
5
Order Service – Order
history
6
Catalog Service – Basic
product information, such as its name, image, and price
7
Review
Service – Customer reviews
8
Inventory
Service – Low inventory warning
9
Shipping
Service – Shipping options, deadlines, and costs drawn
separately from the shipping provider’s API
10
Recommendation
Service(s) – Suggested items
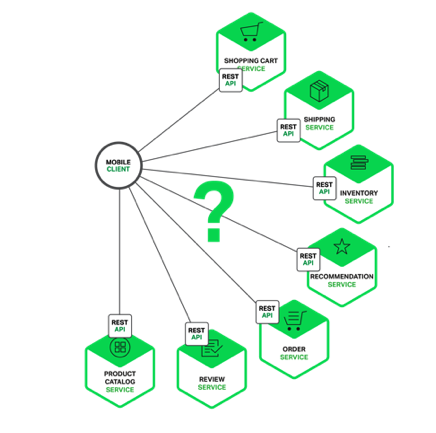
We need to decide how the mobile
client accesses these services. Let’s look at the options.
Direct Client-to-Microservice
Communication
In theory, a client could make
requests to each of the microservices directly. Each microservice would have a
public endpoint (https://serviceName.api.company.name). This URL would
map to the microservice’s load balancer, which distributes requests across the
available instances. To retrieve the product details, the mobile client would make
requests to each of the services listed above.
Unfortunately, there are challenges
and limitations with this option. One problem is the mismatch between the needs
of the client and the fine-grained APIs exposed by each of the microservices.
The client in this example has to make seven separate requests. In more complex
applications it might have to make many more. For example, Amazon describes how
hundreds of services are involved in rendering their product page. While a
client could make that many requests over a LAN, it would probably be too
inefficient over the public Internet and would definitely be impractical over a
mobile network. This approach also makes the client code much more complex.
Another problem with the client
directly calling the microservices is that some might use protocols that are
not web-friendly. One service might use Thrift binary RPC while another service
might use the AMQP messaging protocol. Neither protocol is particularly
browser- or firewall-friendly and is best used internally. An application
should use protocols such as HTTP and WebSocket outside of the firewall.
Another drawback with this approach
is that it makes it difficult to refactor the microservices. Over time we might
want to change how the system is partitioned into services. For example, we
might merge two services or split a service into two or more services. If,
however, clients communicate directly with the services, then performing this
kind of refactoring can be extremely difficult.
Because of these kinds of problems it
rarely makes sense for clients to talk directly to microservices.
Using an API Gateway
Usually a much better approach is to
use what is known as an API Gateway. An
API Gateway is a server that is the single entry point into the system. It
is similar to the Facade pattern from object-oriented design. The API Gateway
encapsulates the internal system architecture and provides an API that is
tailored to each client. It might have other responsibilities such as
authentication, monitoring, load balancing, caching, request shaping and
management, and static response handling.
The following diagram shows how an
API Gateway typically fits into the architecture:
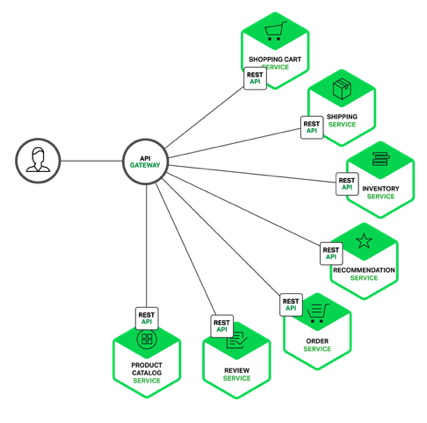
The API Gateway is responsible
for request routing, composition, and protocol translation. All requests from
clients first go through the API Gateway. It then routes requests to the
appropriate microservice. The API Gateway will often handle a request by
invoking multiple microservices and aggregating the results. It can translate
between web protocols such as HTTP and WebSocket and web-unfriendly protocols
that are used internally.
The API Gateway can also provide
each client with a custom API. It typically exposes a coarse-grained API for
mobile clients. Consider, for example, the product details scenario. The
API Gateway can provide an endpoint (/productdetails?productid=xxx) that
enables a mobile client to retrieve all of the product details with a single
request. The API Gateway handles the request by invoking the various
services – product info, recommendations, reviews,
etc. – and combining the results.
A great example of an
API Gateway is the Netflix
API Gateway. The Netflix streaming service is
available on hundreds of different kinds of devices including televisions,
set-top boxes, smartphones, gaming systems, tablets, etc. Initially, Netflix attempted
to provide a one-size-fits-all API for their streaming service. However, they discovered that
it didn’t work well because of the diverse range of devices and their unique
needs. Today, they use an API Gateway that provides an API tailored for
each device by running device-specific adapter code. An adapter typically
handles each request by invoking on average six to seven backend services. The
Netflix API Gateway handles billions of requests per day.
Benefits and Drawbacks of an API
Gateway
As you might expect, using an
API Gateway has both benefits and drawbacks. A major benefit of using an
API Gateway is that it encapsulates the internal structure of the application.
Rather than having to invoke specific services, clients simply talk to the
gateway. The API Gateway provides each kind of client with a specific API.
This reduces the number of round trips between the client and application. It
also simplifies the client code.
The API Gateway also has some
drawbacks. It is yet another highly available component that must be developed,
deployed, and managed. There is also a risk that the API Gateway becomes a
development bottleneck. Developers must update the API Gateway in order to
expose each microservice’s endpoints. It is important that the process for
updating the API Gateway be as lightweight as possible. Otherwise,
developers will be forced to wait in line in order to update the gateway.
Despite these drawbacks, however, for most real-world applications it makes
sense to use an API Gateway.
Implementing an API Gateway
Now that we have looked at the
motivations and the trade-offs for using an API Gateway, let’s look at
various design issues you need to consider.
Performance and Scalability
Only a handful of companies operate
at the scale of Netflix and need to handle billions of requests per day.
However, for most applications the performance and scalability of the
API Gateway is usually very important. It makes sense, therefore, to build
the API Gateway on a platform that supports asynchronous, non-blocking
I/O. There are a variety of different technologies that can be used to
implement a scalable API Gateway. On the JVM you can use one of the
NIO-based frameworks such Netty, Vertx, Spring Reactor, or JBoss Undertow.
One popular non-JVM option is Node.js, which is a platform built on Chrome’s
JavaScript engine. Another option is to use NGINX Plus.
NGINX Plus offers a mature, scalable, high-performance web server and
reverse proxy that is easily deployed, configured, and programmed.
NGINX Plus can manage authentication, access control, load balancing
requests, caching responses, and provides application-aware health checks and
monitoring.
Using a Reactive Programming Model
The API Gateway handles some
requests by simply routing them to the appropriate back-end service. It handles
other requests by invoking multiple back-end services and aggregating the
results. With some requests, such as a product details request, the requests to
back-end services are independent of one another. In order to minimize response
time, the API Gateway should perform independent requests concurrently.
Sometimes, however, there are dependencies between requests. The
API Gateway might first need to validate the request by calling an
authentication service, before routing the request to a back-end service.
Similarly, to fetch information about the products in a customer’s wish list,
the API Gateway must first retrieve the customer’s profile containing that
information, and then retrieve the information for each product. Another
interesting example of API composition is the Netflix Video Grid.
Writing API composition code using
the traditional asynchronous callback approach quickly leads you to callback
hell. The code will be tangled, difficult to understand, and error-prone. A
much better approach is to write API Gateway code in a declarative style
using a reactive approach. Examples of reactive abstractions include Future in Scala, CompletableFuture in Java 8, and Promise in JavaScript. There is also Reactive Extensions (also called Rx or ReactiveX),
which was originally developed by Microsoft for the .NET platform. Netflix
created RxJava for the JVM specifically to use in their API Gateway. There
is also RxJS for JavaScript, which runs in both the browser and Node.js. Using
a reactive approach will enable you to write simple yet efficient
API Gateway code.
Service Invocation
A microservices-based application is
a distributed system and must use an inter-process communication mechanism.
There are two styles of inter-process communication. One option is to use an
asynchronous, messaging-based mechanism. Some implementations use a message
broker such as JMS or AMQP. Others, such as Zeromq, are brokerless and the
services communicate directly. The other style of inter-process communication
is a synchronous mechanism such as HTTP or Thrift. A system will typically use
both asynchronous and synchronous styles. It might even use multiple
implementations of each style. Consequently, the API Gateway will need to
support a variety of communication mechanisms.
Service Discovery
The API Gateway needs to know
the location (IP address and port) of each microservice with which it
communicates. In a traditional application, you could probably hardwire the
locations, but in a modern, cloud-based microservices application this is a
non-trivial problem. Infrastructure services, such as a message broker, will
usually have a static location, which can be specified via OS environment
variables. However, determining the location of an application service is not
so easy. Application services have dynamically assigned locations. Also, the
set of instances of a service changes dynamically because of autoscaling and
upgrades. Consequently, the API Gateway, like any other service client in the
system, needs to use the system’s service discovery mechanism: either Server-Side Discovery or Client-Side Discovery. A later article will describe service discovery in more
detail. For now, it is worthwhile to note that if the system uses Client-Side
Discovery then the API Gateway must be able to query the Service Registry, which is a database of all microservice instances and their
locations.
Handling Partial Failures
Another issue you have to address
when implementing an API Gateway is the problem of partial failure. This
issue arises in all distributed systems whenever one service calls another
service that is either responding slowly or is unavailable. The
API Gateway should never block indefinitely waiting for a downstream
service. However, how it handles the failure depends on the specific scenario
and which service is failing. For example, if the recommendation service is
unresponsive in the product details scenario, the API Gateway should
return the rest of the product details to the client since they are still
useful to the user. The recommendations could either be empty or replaced by,
for example, a hardwired top ten list. If, however, the product information
service is unresponsive then API Gateway should return an error to the
client.
The API Gateway could also
return cached data if that was available. For example, since product prices
change infrequently, the API Gateway could return cached pricing data if
the pricing service is unavailable. The data can be cached by the
API Gateway itself or be stored in an external cache such as Redis or
Memcached. By returning either default data or cached data, the
API Gateway ensures that system failures do not impact the user
experience.
Netflix Hystrix is an incredibly useful library for writing code that invokes
remote services. Hystrix times out calls that exceed the specified threshold.
It implements a circuit breaker pattern, which stops the client from
waiting needlessly for an unresponsive service. If the error rate for a service
exceeds a specified threshold, Hystrix trips the circuit breaker and all
requests will fail immediately for a specified period of time. Hystrix lets you
define a fallback action when a request fails, such as reading from a cache or
returning a default value. If you are using the JVM you should definitely
consider using Hystrix. And, if you are running in a non-JVM environment, you
should use an equivalent library.
Summary
For most microservices-based applications, it makes sense
to implement an API Gateway, which acts as a single entry point into a
system. The API Gateway is responsible for request routing, composition,
and protocol translation. It provides each of the application’s clients with a
custom API. The API Gateway can also mask failures in the back-end
services by returning cached or default data. In the next article in the
series, we will look at communication between services.
http://microservices.io/patterns/apigateway.html
Pattern: API
Gateway
Context
Let's imagine you are
building an online store that uses the Microservices pattern and that you are implementing the product details page. You
need to develop multiple versions of the product details user interface:
▪
HTML5/JavaScript-based UI
for desktop and mobile browsers - HTML is generated by a server-side web
application
▪
Native Android and iPhone
clients - these clients interact with the server via REST APIs
In addition, the online
store must expose product details via a REST API for use by 3rd party
applications.
A product details UI can
display a lot of information about a product. For example, the Amazon.com
details page for POJOs in Action displays:
▪
Basic information about
the book such as title, author, price, etc.
▪
Your purchase history for
the book
▪
Availability
▪
Buying options
▪
Other items that are
frequently bought with this book
▪
Other items bought by
customers who bought this book
▪
Customer reviews
▪
Sellers ranking
▪
...
Since the online store
uses the Microservices pattern the product details data is spread over multiple
services. For example,
§
Product Info Service -
basic information about the product such as title, author
§
Pricing Service - product
price
§
Order service - purchase
history for product
§
Inventory service -
product availability
§
Review service - customer
reviews ...
Consequently, the code
that displays the product details needs to fetch information from all of these
services.
Problem
How do the clients of a
Microservices-based application access the individual services?
Forces
§
The granularity of APIs
provided by microservices is often different than what a client needs.
Microservices typically provide fine-grained APIs, which means that clients
need to interact with multiple services. For example, as described above, a
client needing the details for a product needs to fetch data from numerous
services.
§
Different clients need
different data. For example, the desktop browser version of a product details
page desktop is typically more elaborate then the mobile version.
§
Network performance is
different for different types of clients. For example, a mobile network is
typically much slower and has much higher latency than a non-mobile network.
And, of course, any WAN is much slower than a LAN. This means that a native
mobile client uses a network that has very difference performance
characteristics than a LAN used by a server-side web application. The
server-side web application can make multiple requests to backend services
without impacting the user experience where as a mobile client can only make a
few.
§
The number of service
instances and their locations (host+port) changes dynamically
§
Partitioning into services
can change over time and should be hidden from clients
Solution
Implement an API gateway
that is the single entry point for all clients. The API gateway handles
requests in one of two ways. Some requests are simply proxied/routed to the
appropriate service. It handles other requests by fanning out to multiple
services.
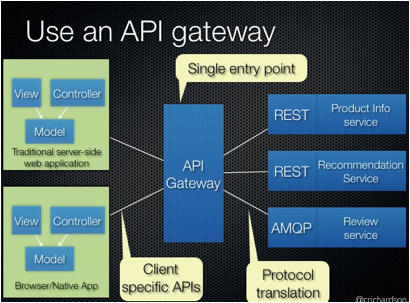
Rather than provide a
one-size-fits-all style API, the API gateway can expose a different API for
each client. For example, the Netflix API gateway runs client-specific adapter code that provides each
client with an API that's best suited to it's requirements.
The API gateway might also
implement security, e.g. verify that the client is authorized to perform the
request